大话编码
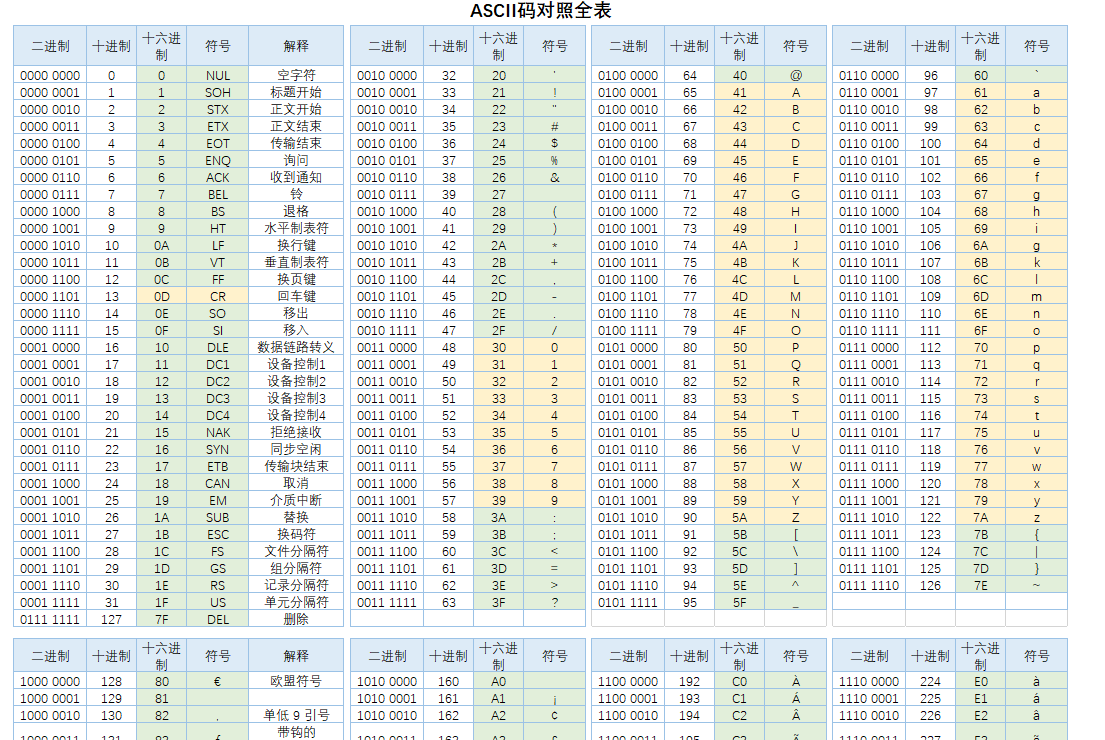
ASCII#
https://en.wikipedia.org/wiki/ASCII
American Standard Code for Information Interchange
1963年第一次发布
由于当时的技术限制,ASCII只有128项, 其中95个是可打印字符。虽然Unicode有上百万项,但其前128项跟ASCII是一样的。
GBK#
中国在很早就制定了国家的编码标准,并不断演进修订。
| 编码 | 字符数 | 发行时间 |
|---|---|---|
| GB2312/CP936 | 6,763 | 1980年 |
| GBK | 21,003 | 1995年 |
| GB18030-2000 | 27,533 | 2000年 |
| GB18030-2005 | 70,244 | 2005年 |
| GB18030-2022 | 87,887 | 2022年 |
https://zh.wikipedia.org/wiki/GB_18030
各种其它语言的编码#
- Big5虽普及于台湾、香港、澳门等繁体中文区域,但长期以来并非当地的国家/地区标准或官方标准,而只是业界标准。 倚天中文系统、Windows繁体中文版等主要操作系统的字符集都是以Big5为基准,但厂商又各自增加不同的造字与造字区,派生成多种不同版本。
- Shift_JIS是日本电脑系统常用的编码表,能容纳全形及半形拉丁字母、平假名、片假名、符号及日语汉字。
- KS X 1001是韩国用于书写的谚文和汉字的字符编码规格,包含谚文2,350字、汉字4,888字、英文字母、数字和假名共,8226字。
乱码是如何产生的#
一个典型的场景是通过SSH连接到服务器后打开vi来编辑文件,其字符显示流程如下图:
+--------------+ +--------------+ +--------------+ +--------------+ +--------------+
| File System |-->| Operating Sys|-->|Server App(vi)|-->| SSH Proto |-->|Client SSH App|--> Display
+--------------+ +--------------+ +--------------+ +--------------+ +--------------+
| Read File | 读取数据块 | 解码并显示字符 | 网络传输 | 解码并显示字符
假设文件内容编码为GBK,而vi认为其编码为ascii时,就可能显示乱码。
如果vi也认为编码为GBK,则vi可以正确显示,但若客户端的ssh程序认为传输过来的字符是ascii编码时,也会显示乱码。
ISO8859-1#
正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”。
它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。
由于其编码范围大,所以大部分二进制数据都会映射到字符上。
在早期服务器系统上,如果没有安装UTF-8编码,我们会设置编码为ISO8859-1,让服务器上的程序可以正常打开其它编码的文件。
再将客户端ssh程序设置为正确的编码,则可以通过ssh查看其它编码的文件。
Unicode#
正式名称:The Unicode Standard
将世界大部分书写系统的字符编码到一起
最新版15.0,包含149,186个字符,涵盖了当代和历史上的161个符号系统,3664个表情符号和控制符号
Unicode划分#
-
U+0000至U+FFFF: 基本多文种平面 B-BlockBMCOL
- 0F00-0FFF 藏文
- 2F00-2FDF 康熙部首
- 3000-303F 中日韩符号和标点
- 4DC0-4DFF 易经六十四卦符号
- 4E00-9FFF 中日韩统一表意文字
-
U+10000~U+1FFFF: 第一辅助平面又称多文种补充平面 B-BlockBMCOL
- 12000-123FF 楔形文字
- 13000-1342F 埃及圣书体
- 17000-187FF 西夏文
- 18B00-18CFF 契丹小字
- 1D300-1D35F 太玄经符号
- 1F000-1F02F 麻将牌
- 1F030-1F09F 多米诺骨牌
- 1F0A0-1F0FF 扑克牌
- 1F700-1F77F 炼金术符号
其它辅助平面#
- U+20000~U+2FFFF:第二辅助平面又称为表意文字补充平面
整个平面配置的都是一些罕用的汉字或地区的方言用字,如粤语用字及越南语的字喃。
现时摆放了“中日韩统一表意文字扩展B区”(4万3253个汉字)、
- “中日韩统一表意文字扩展C区”(4149个汉字)、
- “中日韩统一表意文字扩展D区”(222个汉字)、
- “中日韩统一表意文字扩展E区”(5762个汉字)、
- “中日韩统一表意文字扩展F区”(7473个汉字)以及
- 中日韩兼容表意文字增补(CJK Compatibility Ideographs Supplement)
- U+30000~U+3FFFF:第三辅助平面已有相关编码提案。 本平面现已用来摆放汉字扩展区G和H,并规划用于摆放甲骨文、金文、小篆、中国战国时期文字等 U+32400至U+352FF:小篆(提案已提交) U+35400至U+36BFF:甲骨文(提案已提交)
UTF-8#
Unicode诞生后,需要2个字节才能表示一个字符(加上辅助平面则需要3个字节)。
对于英文文档来说,单字节的ASCII已经足够,改为Unicode则文档直接变大2倍,传输和存储都会造成空间的浪费。
UTF-8编码#
| 起始 | 终止 | 字节数 | Byte1 | Byte2 | Byte3 | Byte4 | Byte5 | Byte6 |
|---|---|---|---|---|---|---|---|---|
| U+0000 | U+07F | 1 | 0xxxxxxx | |||||
| U+0080 | U+07FF | 2 | 110xxxxx | 10xxxxxx | ||||
| U+0800 | U+FFFF | 3 | 1110xxxx | 10xxxxxx | 10xxxxxx | |||
| U+10000 | U+1FFFFF | 4 | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | ||
| U+200000 | U+3FFFFFF | 5 | 111110xx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | |
| U+4000000 | U+7FFFFFFF | 6 | 1111110x | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
UTF-8 的 ASCII 字符只占用一个字节,比较节省空间,但是更多字符的 UTF-8 编码占用的空间就要多出1/2,特别是中文、日文和韩文(CJK)这样的方块文字,它们大多需要三个字节。
MySQL utf8mb4#
MySQL字符编码集中有两套UTF-8编码实现:“utf8”和“utf8mb4”,其中“utf8”是一个字最多占据3字节空间的编码实现; 而“utf8mb4”则是一个字最多占据4字节空间的编码实现,也就是UTF-8的完整实现。
这是由于MySQL在4.1版本开始支持UTF-8编码(当时参考UTF-8草案版本为RFC 2279)时,为2003年,并且在同年9月限制了其实现的UTF-8编码的空间占用最多为3字节,而UTF-8正式形成标准化文档(RFC 3629)是其之后。
限制UTF-8编码实现的编码空间占用一般被认为是考虑到数据库文件设计的兼容性和读取最优化,但实际上并没有达到目的, 而且在UTF-8编码开始出现需要存入非基本多文种平面的Unicode字符(例如emoji字符)时导致无法存入(由于3字节的实现只能存入基本多文种平面内的字符)。
直到2010年在5.5版本推出“utf8mb4”来代替、“utf8”重命名为“utf8mb3”并调整“utf8”为“utf8mb3”的别名,并不建议使用旧“utf8”编码,以此修正遗留问题。